Backburner Month 25: Potrero and Treant and others
This is an entry from a list of projects I hope to some day finish. Return to the backburnered projects index.
Edit (2024-09-03): One of the projects described below has something resembling a proper release! The Matzo language has a reasonably usable version available on Github or to try in the browser. For more details, see this blog post about the language.
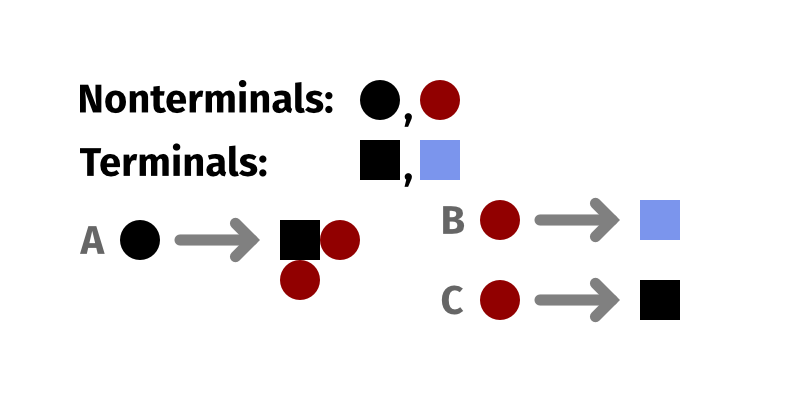
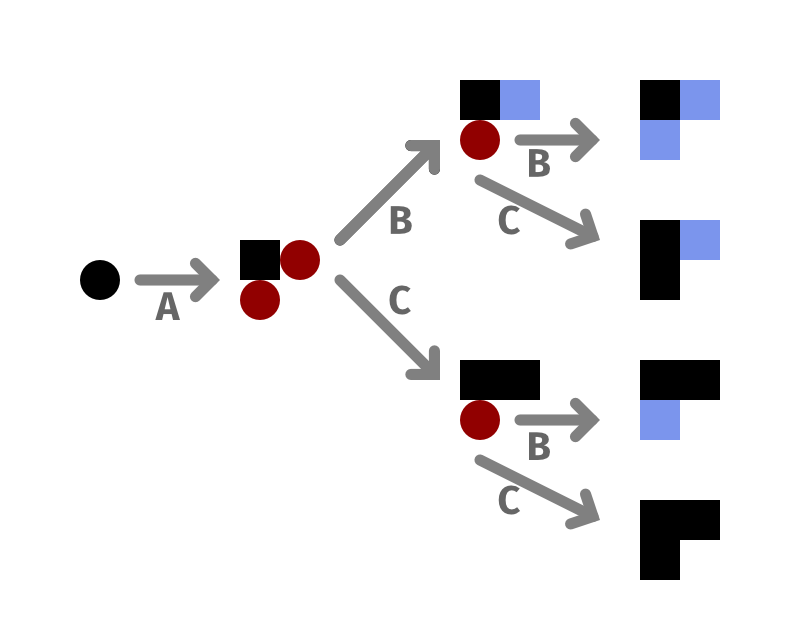
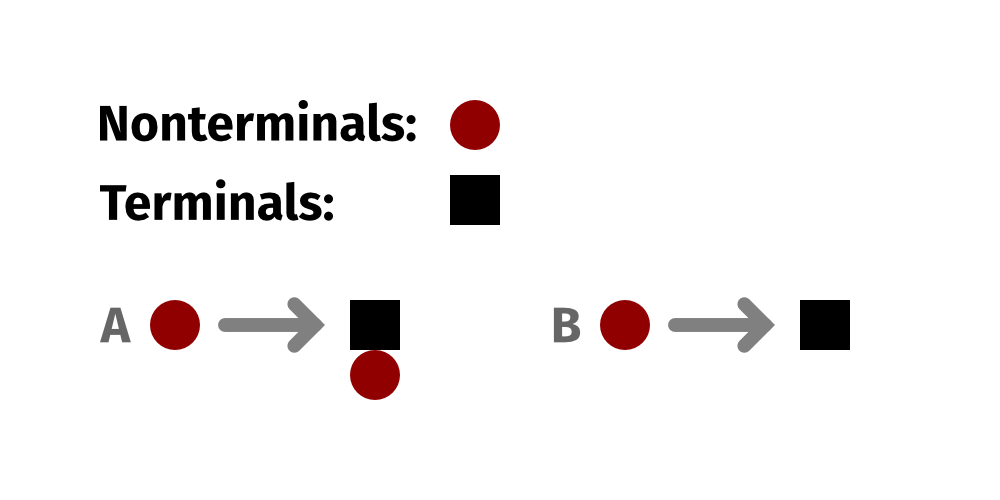
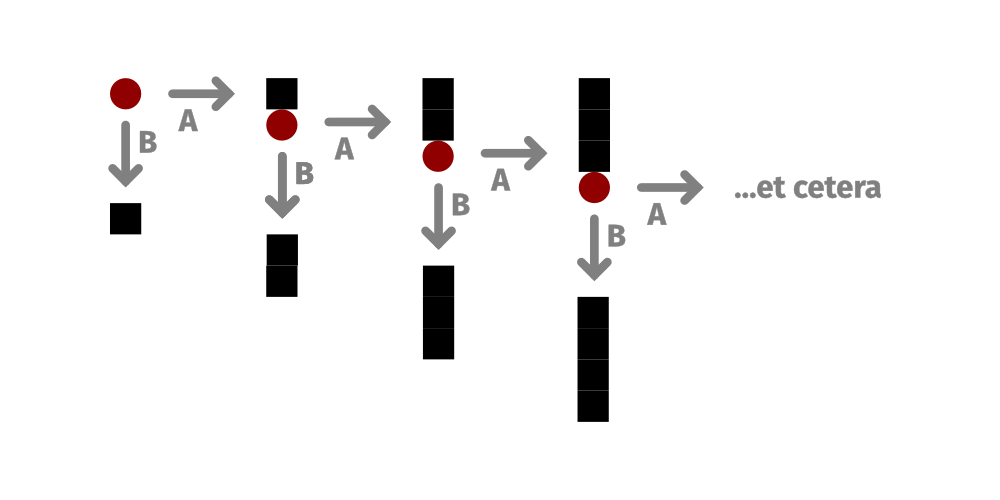
What is it? Various programming-language-centric approaches to procedural generation. I've done a lot of these, and Potrero and Treant are two of the newest ones, but I'm using this to talk about the whole family of these tools.
My approach here is to build tools for procedural generation as programming languages, and usually specifically as functional or logical languages: the UI is fundamentally text-centric, based on writing bits of structured text, and the operations defined can be broken down into atomic units that can be understood and reasoned about in isolation without having to reason about broader state. Additionally, because they are ideally decidable—i.e. you can ensure that they don't loop forever, but instead will always complete in a finite amount of time—you get a lot of ability to statically analyze them.
I think there's a really interesting design space here, and different experiments have focused on exposing them in different ways. There are some thoughts in common between all of them:
- I think (as mentioned) that decidability is important here, both because “this will never loop forever” is a nice property but also because it opens the way for some sophisticated static analysis, like, “Will this program ever produce output with such-and-such a property?”
- I think mostly-pure functional programming is a useful way to think about these things, where the only side effect is non-determinism
- I think there's some interesting inspiration to be taken from logic programming or answer-set programming (c.f. Smith & Mateas, Answer Set Programming for Procedural Content Generation: A Design Space Approach and also Karth & Smith, WaveFunctionCollapse is Constraint Solving in the Wild)
- I think there's a lot of API work to be done around exposing common resources (like Darius Kazemi's corpora) as “standard libraries” to draw on
- I think there's also a lot of API work to be done around the right primitives for structuring output either textually or non-textually (although I'll freely admit that there's research here that I'm not conversant with!)
So the goal of my various tools has been to chip away at this space and experiment with these various theses!
Why write it? The big tool in this space right now is Tracery. Tracery is a great tool and I love it. That said, I'm very picky about tools.
To give an example of what I mean, here's an example of a Tracery program which creates a brief description of meeting a person:
{
"origin": ["#[#setNoun#]story#"],
"setNoun": [
"[person:man][them:him]",
"[person:woman][them:her]",
"[person:person][them:them]"],
"adj": ["familiar", "strange", "mysterious"],
"adv": ["warmly", "cautiously", "profusely"],
"story": ["You meet a #adj# #person#. You greet #them# #adv#."]
}
You'll notice that the syntax is all JSON, with all the advantages and disadvantages that brings: it's a universally available format, which is good, but it's also more finicky and particular, and also now important syntax is embedded in the string literals in a way that's not (for example) syntax-highlighted by default. Note also the "setNoun" rule above: what this does is actually create new rules effectively by injecting them into the set of rules, so depending on which choice is made, it'll define the rule "noun" as being either "man", "woman", or "person", and define "them" as being a corresponding pronoun.
Here's the same generator expressed in Matzo, a dynamically typed programming language for procedural generation that was also the very first tool I built along these lines:
person := "man" | "woman" | "person";
pronoun :=
{ "man" => "him"
; "woman" => "her"
; "person" => "them"
};
adj ::= familiar unfamiliar mysterious;
adv ::= warmly cautiously profusely;
n := person; fix n;
puts "You come across a " adj " " n ".";
puts "You greet " pronoun.n " " adv ".";
This has a lot of little convenience features, like the ::= taking a set of bare words that are implicitly understood to be a disjunction. (Indeed, you could rewrite the first line of the program to person ::= man woman person; and it would have the same meaning: I wrote it with := to showcase both approaches.) It also has functions—the value of pronoun is a function which branches on its argument—and the fix operation, which takes a rule which otherwise would be vary, evaluates it once, and modifies its value to be the result of that: i.e. after that line, person will still randomly be one of three values, but n will always deterministically be one of those three values.
After Matzo, I worked on a tool called Latka which was similar but with a light static type system. You'll notice this one relies more heavily on things like (structurally typed) algebraic data types and helper functions to assemble sentences, like pa for a paragraph or se for a sentence. You might also notice that fixed is no longer a thing which changes an existing rule, but a property of the binding site of the variable.
let gender = M | F | N
let noun M = "man"
| noun F = "woman"
| noun N = "person"
let them M = "him"
| noun F = "her"
| noun N = "them"
let adj = %{familiar unfamiliar mysterious}
let adv = %{warmly cautiously profusely}
let main =
let fixed n = gender
pa.[
se.["You come across a", adj, noun.n],
se.["You greet", them.n, adv],
]
These obviously have tradeoffs relative to Tracery, but they more closely match the way I think about these problems and the way I'd naturally gravitate towards solving them. That said, I also don't think they're competing: in fact, one thing I've wanted to do (but never finished a prototype of) is building cross-calling between them: I'd love to be able to directly include a Tracery program in a Latka program and vice versa.
As with other projects I've described, I think that the affordances of functional or expression-oriented programming have a lot of benefits, and I think decidable programming languages are really useful. And of course, one reason I want to write it is that I love random generation of things.
There's a reason this project is also the last backburner post: it's the project I most regret having left on the backburner, and the one I would love to spend more time on soon once I develop motivation to do so again.1
Why the name? Latka and Matzo were named together but otherwise chosen at random. I was originally gonna call another experimental language Mesa, which is Spanish for 'table' (by analogy with random tables you'd find in an RPG book) but there's already a graphics driver suite called mesa. So I decided to choose the name of a related geographical phenomenon, since a potrero is a kind of mesa. Similarly, the original version of Treant was designed around probabalistic tree rewriting, and treant is a name used in fantasy role-playing games to refer to a public-domain equivalent to Tolkien's Ents.
#backburner #tool #language #procedural
- Hell, I've even given a talk about these before—although a bad one which I'm thankful wasn't recorded, since I was feverish and recovering from a throad infection at the time—and I never did release Latka in a usable format afterwards, which is an ambient regret of mine. I would love to go back and release one of these properly instead!