This is an entry from a list of projects I hope to some day finish. Return to the backburnered projects index.
What is it? A language for expressing recipes in graph form.
The usual presentation of a recipe is as a snippet of prose, doing things step-by-step. However, actual recipes aren't strictly linear: there are often parallel preparations that need to be done, like making a roux while the sauce simmers elsewhere. Prose is certainly capable of capturing this—prose is, after all, a default way of representing information for a good reason—but I'm also fond of notation and alternative ways of representing information. What if we could make the various branches of a recipe more explicit?
Apicius is a way of writing recipes that encodes explicit parallel paths. It looks more like a programming language:
eggplant rougail {
[2] eggplants
-> scoop flesh, discard skin
-> mash
-> $combine
-> mix & [4bsp] oil
-> DONE;
[2] white onions or shallots -> mince -> $combine;
[2] hot peppers -> mince -> $combine;
}
How do we read this? Well, the bit before the curly braces is the name of the recipe: eggplant rougail. Inside the curly braces, we have a set of paths, each of which ends with a semicolon. The beginning of every path starts with one or more raw ingredients, with the amount set apart with square brackets. Once you're in a path, there are two things you can write: steps, which look like plain text, or join points, which start with a dollar sign.
What is a join point? It's a place where you combine multiple previously-separate preparations. In the above example, you have three different basic ingredients: eggplants, peppers, and onions or shallots. Each is prepared separately, and then later on mixed together: the join point indicates where the ingredients are combined.
There's also a fourth ingredient at one point above: at any given step or join point, you can add extra ingredients with &. The intention is that these are staples which require no initial preparation or processing: it's where you'd specify salt or pepper or oil in most recipes, ingredients which sometimes might not even make it onto the initial ingredients list because they're so simple and obvious.
Finally, there's a special step called DONE, which is always the last step.
In the above example, there's a relatively simple pattern happening: three ingredients are prepared and then joined. But with different uses of join points, you can express recipes that have multiple separate preparations that come together in a specific way, and that parallelism is now apparent in the writing. Here is a different recipe:
egg curry {
[8] eggs -> boil 10m -> $a;
[2] onions -> mince -> brown &oil -> stir -> $b;
[2] garlic cloves + [1] piece ginger + [1] hot pepper + salt + pepper -> grind -> $b;
[4] ripe tomatoes -> chop -> $c;
$b -> stir &thyme -> $c;
$c -> simmer 5m &saffron -> $a;
$a -> stir 10m -> simmer 5m &water -> halve -> DONE;
}
This is rather more complicated! In particular, we now have three different join points, and a larger number of basic ingredients (combined with +). In parallel, we can boil the eggs, mince and brown the onions, grind seasonings together, and chop the tomatoes. The first two disparate sequences to join are actually the browned onions and the garlic/ginger/pepper/&c mixture: those are combined with some thyme, and afterwards the tomatoes are mixed in; after simmering with saffron, the boiled eggs are added, then all paths are joined.
I don't think this is terribly easy to follow in this format, especially when using non-descriptive join point names like $a. However, an advantage of this format is that it's machine-readable: this format can be ingested and turned into a graphic, like this:
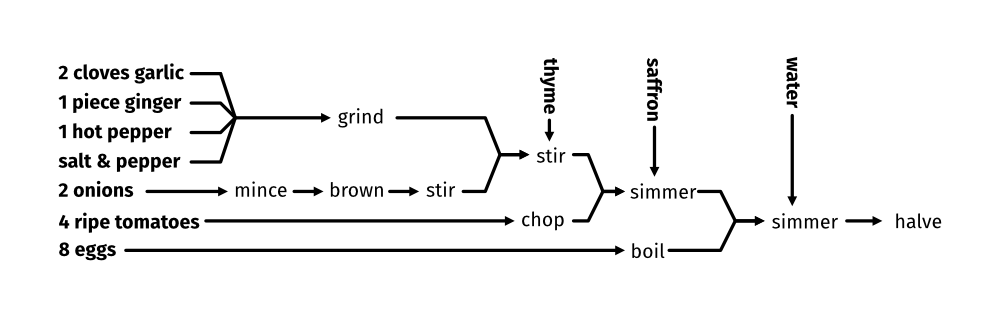
or a table, like this:
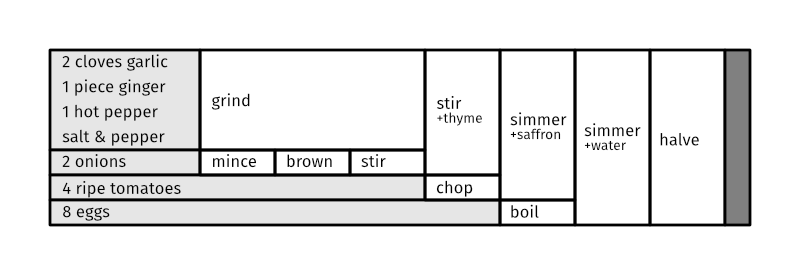
or possibly even into a prose description, using natural language generation techniques to turn this into a more typical recipe. Marking the amounts in square brackets might also allow for automatic resizing of the recipe (although how to do this correctly for baking recipes—where linearly scaling the ingredients can result in an incorrect and non-working recipe—is a can of worms I haven't even considered opening yet.)
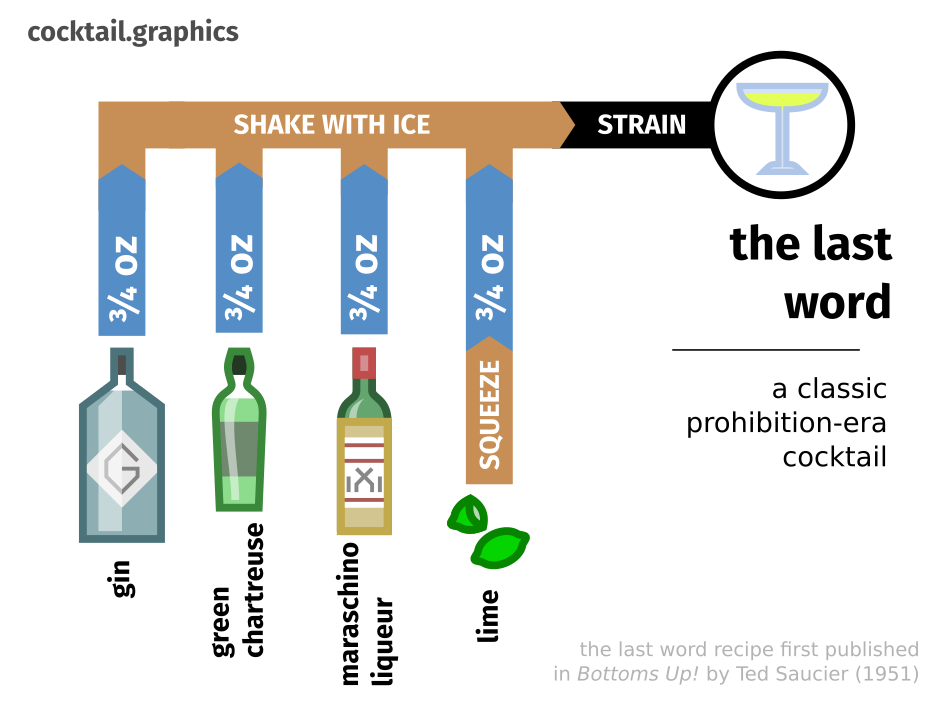
Why write it? Well, I love the presentation of recipes as graphs. I've actually got a whole web site of cocktail recipes in this form, which you can find at the domain cocktail.graphics, and I would love to get to the point that I could semi-automatically generate these diagrams from a snippet of Apicius:
But I think—as I mentioned when I described the language for Parley—that there are many cool things you can do if you have generic data that can be re-interpreted and revisualized. As mentioned above, there are lots of ways you can take this format and use it to represent various structures. What I'd like to do, once I have the tooling to do so, is take a bunch of my favorite recipes (like sundubu-jjigae or ševid polow or jalapeño cream sauce) and convert them into Apicius, and then have some kind of front-end which can be used to view the same recipes using many different rendered formats.
Why the name? One of the few Latin-language cookbooks we have remaining copies of is usually called Apicius, although it's also referred to as De re coquinaria, which boringly translates to “On the topic of cooking.” It's not clear who Apicius was or if the Apicius referenced by the book was a single person who really existed: it may have been written by an otherwise-unattested person named Caelius Apicius, or it may have been named in honor of the 1st-century gourmet Marcus Gavius Apicius, or perhaps it was even authored by a group of people. (It doesn't help that the remaining copies we have are from much later and were probably copied down in the 5th century.)
#backburner #software #tool